Patterns for Vision on the Edge - Part 1 - Concurrent processing
Challenges in implementing Vision based solution using Python on Edge.
Source Code

While developing a solution for implementing vision on the edge use case, one of the most common requirement is having the ability to ingest live video feed and process it to derive useful insights (running a ML model on the captured frame, etc.).
One of the key challenges faced during the implementation was with the ability to simultaneously consume a live video feed from the video source, enable a smooth streaming experience for consumer as well as perform realtime analysis of the video frames. As processing of frame can happen at different rate than reading a frame from camera, handling back-pressure between consumer and producer becomes an important requirement.
We can breakdown the problem into three parts:
- Simultaneous reading and processing of frame.
- Handling back-pressure between frame producer and consumer.
- Transmitting frames to multiple consumers at different rates - Consumer 1 - To process frame; Consumer 2 - To display in UI.
This article covers the first two parts of the problem described above. The third part of the problem will be covered in Part 2 of the blog series.
Design
A possible design for the vision on edge use case is as follows:
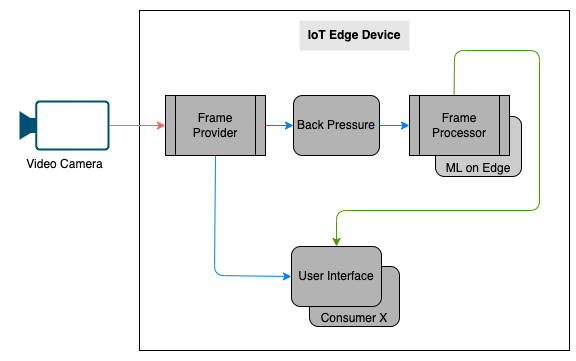
The solution contains primarily a video camera and an edge device.
Frame Providerreads the frame from the video camera at a desired FPS.- The
Frame Providerthen transmits the frames toUser Interfaceto display live video feed at a different FPS. - At the same time, the
Frame Providertransmits the same frame viaBack PressuretoFrame Processorto derive useful insights at the rate thatFrameProcessorcan handle. Frame Processorthen processes the frame and publishes the result to theUser Interface.
Object detection Sample Application
The sample provided is an implementation of the above design. The FrameProvider reads the frames from video file at 30 FPS and send those to User Interface through websocket at 15 FPS and simultaneously puts the frame in a Queue (this is discussed in detail in subsequent section) at 5 FPS. The FrameProcessor reads the frame from the queue and performs object detection using Tiny YOLO ML Model. The UI displays the video feed and the rate at which it received the frame from the server.
Running the sample
Prerequisite
To execute the sample, the developer machine must have either -
OR
Steps
- Clone the repository.
- Prepare environment.
- If using Docker and Visual Studio Code, open the repository in Visual Studio Code Remote - Containers following this guide
- Or in case of using Python, install the required packages using pip
- Run command
python main.pyfrom multiprocessing to start the sample. - The video feed will be shown in User Interface, via ULR http://localhost:7001/.
- The time taken by the ML model to process the frame will be shown in the Console.
Technical Approaches
The first challenge is to enable simultaneous execution of Frame Provider and Frame Processor.
In Python this can be achieved by using the threading or multiprocessing.
Threading
The threading folder contains implementation of this using threading module.
Two threads are created, one to execute FrameProvider and another to execute FrameProcessor. Python’s Queue is used as communication layer between threads. FrameProvider captures the frame from video file, writes it to the queue and sends the frame to UI. FrameProcessor processes the message from queue and performs object detection on each frame. It prints the time it takes to perform inference in the terminal.
We can execute this by running python main.py from threading folder.

You will notice that video stream is not so smooth as expected. The UI shows it is receiving only 3 to 7 frames per second where as we have configured 15 FPS.
self.frame_rate_camera = 30 # FPS rate to read from camera/file
self.frame_rate_ui = 15 # FPS rate of the User Interface
self.frame_rate_queue = 5 # FPS rate to write frame to Queue
So what went wrong here? Let’s see how Python GIL (global interpreter lock) is related to this problem. Python GIL, as per definition : The mechanism used by the CPython interpreter to assure that only one thread executes Python bytecode at a time
Basically the GIL is a global lock that is used to protect the Python interpreter from being acquired by multiple threads simultaneously. If a thread is being executed, no other threads will be able to acquire GIL and run simultaneously.
To relate this to our sample, the FrameProcessor performs a long running task of object detection. In my system each inference takes approximately 0.2-0.3 seconds. So while the model is executing, GIL has been acquired by the FrameProcessor thread. So for this entire duration the FrameProvider was not able to execute and send frame to UI.
The FPS may vary between systems. If the system has better CPU, the model will execute significantly faster. In that case the video sluggishness in UI may not be as apparent. If that happens try looping the
infer(item.frame)call inFrameProcessor._processto simulate more CPU intensive task.
Multiprocessing
Python’s Multiprocessing is another way of executing multiple tasks simultaneously. The multiprocessing folder contains implementation of the solution using multiple processes.
In this sample, FrameProvider and FrameProcessor are executed in two different processes. Multiprocessing.Queue is used to pass frames between processes.
Execute the application by running python main.py from multiprocessing folder.

You will notice the video feed is much more smoother than the threading example. Also notice the FPS is constant at 15, which is matching our configuration.
Why it worked as expected while using multiprocessing? The scope of GIL is a process. Since multiprocessing create subprocesses by spawning/forking, each process gets its own GIL. Due to this the execution of FrameProvider is not impacted by model inference running in a different process.
Back-Pressure Handling
Our second challenge was to handle the back-pressure between Frame Provider and Frame Processor processes. First we will see why the back-pressure is getting created.
We know that object detection takes 0.2-0.3 seconds per frame. So even though we are reading 30 frames per second from the source, we cannot perform object detection on all the frames. Therefore we need a way to manage the back-pressure created from FrameProvider.
We have mentioned about a Queue that is leveraged for transmitting the frame from FrameProvider process to FrameProcessor process. We use Queue of maximum size of 1 to handle back-pressure. Whenever FrameProvider is writing to the Queue it will always overwrite the previous frame. In this way whenever FrameProcessor is reading the frame from the Queue it will always get the latest frame.
Conclusion
We have seen how we can leverage python’s multiprocessing bypass GIL to implement a complete computer vision solution. Whenever there is a CPU intensive task and there is need of executing simultaneous task, it is preferable to use multiprocessing instead of threading to avoid issues from GIL.
We will cover how to send frame to multiple consumer simultaneously in next part of this blog series.