Building large scale data ingestion solutions for Azure SQL using Azure databricks - Part 3
Learn why do deadlock happen when inserting large data into Azure SQL from databricks
Source Code

Shoutout to Yennifer Santos and Jes Schultz for providing me guidance on both deadlock and delete issue.
This is the third article of the blog series on data ingestion into Azure SQL using Azure Databricks. In the first post we discussed how we can use Apache Spark Connector for SQL Server and Azure SQL to bulk insert data into Azure SQL. In the second post we saw how bulk insert performs with different indexing strategies and also compared performance of the new Microsoft SQL Spark Connector with the now deprecated Azure SQL Spark Connector.
In this post we will delve deeper into deadlock issue and discuss potential solution to it. Finally we will discuss briefly the challenges we face when we DELETE large amount of data from Azure SQL Database.
We will continue using environment, dataset and scripts from previous posts and the code will be hidden for brevity. You will find the notebooks and all scripts in the github repo linked above.
Deadlocks: How and Why
We start with reporducing the deadlock that we faced earlier. Databricks is resilient enough to retry any task that failed therefore be on lookout for any failed task even if the stage and job succeeds. We have same set of store ids that we are going to use to insert sales data into the database.
def import_table(url, table_name, stores, batch_size, collapse_partitions=False):
try:
df = spark.read.parquet(f"{path}/{table_name}")
df = df.filter(df[table_storesk_map[table_name]].isin(stores))
# Temporary workaround until Issue #5 gets fixed https://github.com/microsoft/sql-spark-connector/issues/5
table_schema = create_valid_table_schema(table_name, df.schema)
df = spark.createDataFrame(df.rdd, table_schema)
print(f"Number of partitions: {df.rdd.getNumPartitions()}")
if collapse_partitions:
df = df.coalesce(1)
t = Timer(text=f"Imported into table {table_name} in : {{:0.2f}} ")
t.start()
df.write.format("com.microsoft.sqlserver.jdbc.spark") \
.mode("append") \
.option("url", url) \
.option("dbtable", f"{schema}.{table_name}") \
.option("user", username) \
.option("password", password) \
.option("tableLock", "false") \
.option("batchsize", batch_size) \
.save()
elapsed = t.stop()
return elapsed
except Exception as e:
print(f"Failed to import into table {table_name}", e)
url = create_url(server_name, "idx")
truncate_tables(url, username, password, tables)
elapsed = import_table(url, table_name, stores[:2], 1048576, False)
In the above example we insert sales data for 2 stores which results in ~11 million records inserted into store_sales table. Whether any deadlocks happened during course of import can be verified by looking at logs in Spark UI.
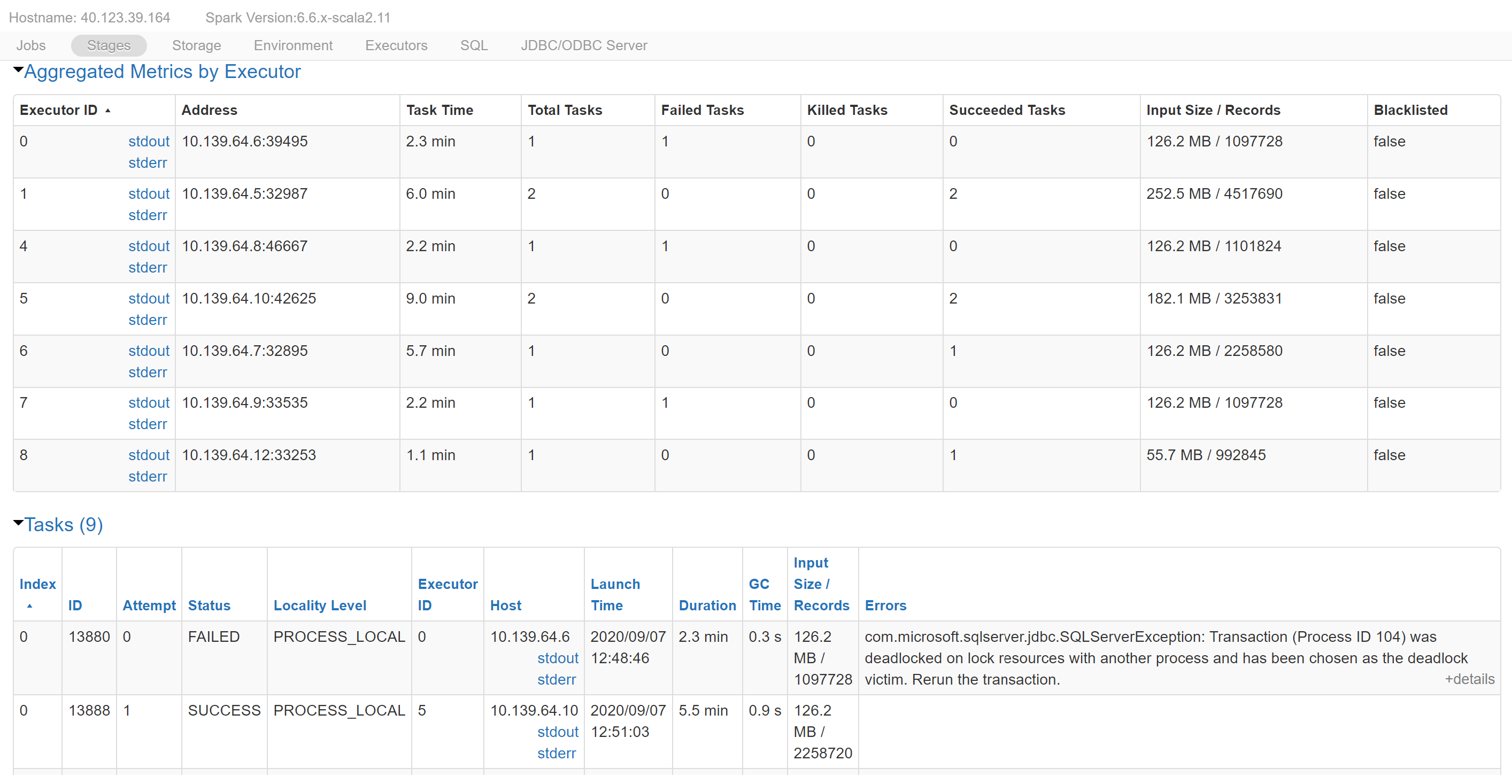
Spark will start with creating 6 tasks, 1 for each partition. All of these tasks will execute concurrently on available workers and each of them will execute Bulk Insert on Azure SQL Database. When these tasks fail as part of deadlock resolution process by database, spark will create new tasks based on its retry policy.
But why do spark create multiple partitions?
There can be many factors which effect how many partitions are created by spark. If the data is read from already paritioned dataset spark will try to maintain the parititons. If the file being read has more than one block spark will read each block into separate partitions. To add to all this number of partitions will also depend on number workers that are available. In our case we read from 2 partitions (because we read 2 stores) and spark reads each of them in 3 partitions (because each file has 3 blocks). This is an optimization which is performed by spark to evenly distribute the dataset across different workers. In general analytics scenario this improves concurrency and performance but it our case it backfires and leads to deadlock. To understand why deadlock happens we need to look deeper into extended events logs.
We can find more details of recently occured deadlocks on Azure SQL Server by executing below query against master database.
WITH CTE AS (
SELECT CAST(event_data AS XML) AS [target_data_XML]
FROM sys.fn_xe_telemetry_blob_target_read_file('dl',
null, null, null)
)
SELECT TOP 10 target_data_XML.value('(/event/@timestamp)[1]',
'DateTime2') AS Timestamp,
target_data_XML.query('/event/data[@name=''xml_report'']
/value/deadlock') AS deadlock_xml,
target_data_XML.query('/event/data[@name=''database_name'']
/value').value('(/value)[1]', 'nvarchar(100)') AS db_name
FROM CTE
ORDER BY Timestamp DESC
query = """
SELECT top 10 target_data_XML.value('(/event/@timestamp)[1]',
'DateTime2') AS Timestamp,
target_data_XML.query('/event/data[@name=''xml_report'']
/value/deadlock') AS deadlock_xml,
target_data_XML.query('/event/data[@name=''database_name'']
/value').value('(/value)[1]', 'nvarchar(100)') AS db_name
FROM (
SELECT CAST(event_data AS XML) AS [target_data_XML]
FROM sys.fn_xe_telemetry_blob_target_read_file('dl',
null, null, null)
) as x
ORDER BY Timestamp DESC"""
url = create_url(server_name, "master")
dl_df = spark.read \
.format("jdbc") \
.option("url", url) \
.option("query", query) \
.option("user", username) \
.option("password", password).load()
display(dl_df)
<?xml version="1.0" encoding="UTF-8"?>
<deadlock>
<victim-list>
<victimProcess id="process294342d5c28" />
</victim-list>
<process-list>
<process id="process294342d5c28" taskpriority="0" logused="14702332" waitresource="PAGE: 6:5:177139 " waittime="65924" ownerId="6305608" transactionname="implicit_transaction" lasttranstarted="2020-09-07T12:48:46.310" XDES="0x2942da70428" lockMode="IX" schedulerid="2" kpid="32240" status="suspended" spid="104" sbid="0" ecid="0" priority="0" trancount="2" lastbatchstarted="2020-09-07T12:48:46.310" lastbatchcompleted="2020-09-07T12:48:46.310" lastattention="1900-01-01T00:00:00.310" clientapp="Microsoft JDBC Driver for SQL Server" hostname="0825-113128-alum84-10-139-64-6" hostpid="0" loginname="anksinha" isolationlevel="read committed (2)" xactid="0" currentdb="6" currentdbname="idx" lockTimeout="4294967295" clientoption1="671088672" clientoption2="128058">
<executionStack>
<frame procname="unknown" queryhash="0x499421339951eed9" queryplanhash="0xfdb1047943f4774d" line="1" stmtend="1414" sqlhandle="0x020000004f6fb4142b1cd89e697a443fbf5d63241a537a260000000000000000000000000000000000000000">unknown</frame>
</executionStack>
<inputbuf>INSERT BULK dbo.store_sales ([ss_sold_date_sk] INT , [ss_sold_time_sk] INT , [ss_item_sk] INT , [ss_customer_sk] INT , [ss_cdemo_sk] INT , [ss_hdemo_sk] INT , [ss_addr_sk] INT , [ss_store_sk] INT , [ss_promo_sk] INT , [ss_ticket_number] INT , [ss_quantity] INT , [ss_wholesale_cost] DECIMAL(7, 2) , [ss_list_price] DECIMAL(7, 2) , [ss_sales_price] DECIMAL(7, 2) , [ss_ext_discount_amt] DECIMAL(7, 2) , [ss_ext_sales_price] DECIMAL(7, 2) , [ss_ext_wholesale_cost] DECIMAL(7, 2) , [ss_ext_list_price] DECIMAL(7, 2) , [ss_ext_tax] DECIMAL(7, 2) , [ss_coupon_amt] DECIMAL(7, 2) , [ss_net_paid] DECIMAL(7, 2) , [ss_net_paid_inc_tax] DECIMAL(7, 2) , [ss_net_profit] DECIMAL(7, 2) ) with (ROWS_PER_BATCH = 1048576)</inputbuf>
</process>
<process id="process2943205fc28" taskpriority="0" logused="465121144" waitresource="PAGE: 6:5:176838 " waittime="4133" ownerId="6305670" transactionname="implicit_transaction" lasttranstarted="2020-09-07T12:48:46.320" XDES="0x29448a1c428" lockMode="X" schedulerid="2" kpid="54388" status="suspended" spid="107" sbid="0" ecid="0" priority="0" trancount="2" lastbatchstarted="2020-09-07T12:50:13.077" lastbatchcompleted="2020-09-07T12:50:13.077" lastattention="1900-01-01T00:00:00.077" clientapp="Microsoft JDBC Driver for SQL Server" hostname="0825-113128-alum84-10-139-64-5" hostpid="0" loginname="anksinha" isolationlevel="read committed (2)" xactid="0" currentdb="6" currentdbname="idx" lockTimeout="4294967295" clientoption1="671088672" clientoption2="128058">
<executionStack>
<frame procname="unknown" queryhash="0x499421339951eed9" queryplanhash="0xfdb1047943f4774d" line="1" stmtend="1414" sqlhandle="0x020000004f6fb4142b1cd89e697a443fbf5d63241a537a260000000000000000000000000000000000000000">unknown</frame>
</executionStack>
<inputbuf>INSERT BULK dbo.store_sales ([ss_sold_date_sk] INT , [ss_sold_time_sk] INT , [ss_item_sk] INT , [ss_customer_sk] INT , [ss_cdemo_sk] INT , [ss_hdemo_sk] INT , [ss_addr_sk] INT , [ss_store_sk] INT , [ss_promo_sk] INT , [ss_ticket_number] INT , [ss_quantity] INT , [ss_wholesale_cost] DECIMAL(7, 2) , [ss_list_price] DECIMAL(7, 2) , [ss_sales_price] DECIMAL(7, 2) , [ss_ext_discount_amt] DECIMAL(7, 2) , [ss_ext_sales_price] DECIMAL(7, 2) , [ss_ext_wholesale_cost] DECIMAL(7, 2) , [ss_ext_list_price] DECIMAL(7, 2) , [ss_ext_tax] DECIMAL(7, 2) , [ss_coupon_amt] DECIMAL(7, 2) , [ss_net_paid] DECIMAL(7, 2) , [ss_net_paid_inc_tax] DECIMAL(7, 2) , [ss_net_profit] DECIMAL(7, 2) ) with (ROWS_PER_BATCH = 1048576)</inputbuf>
</process>
</process-list>
<resource-list>
<pagelock fileid="5" pageid="177139" dbid="6" subresource="FULL" objectname="1184344b-8c03-4040-beeb-0fe87dbb370f.dbo.store_sales" id="lock293f9709e80" mode="X" associatedObjectId="72057594045267968">
<owner-list>
<owner id="process2943205fc28" mode="X" />
</owner-list>
<waiter-list>
<waiter id="process294342d5c28" mode="IX" requestType="wait" />
</waiter-list>
</pagelock>
<pagelock fileid="5" pageid="176838" dbid="6" subresource="FULL" objectname="1184344b-8c03-4040-beeb-0fe87dbb370f.dbo.store_sales" id="lock29338111d80" mode="IX" associatedObjectId="72057594045267968">
<owner-list>
<owner id="process294342d5c28" mode="IX" />
</owner-list>
<waiter-list>
<waiter id="process2943205fc28" mode="X" requestType="convert" />
</waiter-list>
</pagelock>
</resource-list>
</deadlock>
The XML produced gives a more detail about why deadlock happens. There are two (or more) page locks held by different processes under X (or IX) mode and the processes tries to acquire exclusive lock on each other's pages. Refer to doc to learn more about different lock modes and deadlock.
BULK insert will start by acquiring exclusive(X) row-level lock and intent exclusive (IX) lock on corresponding pages. One way to control this behaviour is by specifying TABLOCK option which will force the session to acquire table-level lock. Which table-level lock is obtained depends upon whether the table has any index on it. If the table has no index (heap table) then Bulk Update log is acquired which allows multiple concurrent bulk import to execute. However if the table has index then IX or X lock is acquired which prevents any other write operations on the table. This documentation provides more detail on how to optimize Bulk Import on Sql Database. However the article is for SQL Server 2008 and few of the recommendation (such as minimizing logging) is not applicable for Azure SQL Server. Nonetheless, the behaviour of bulk insert described in the article is still applicable to Azure SQL Database.
Approaches for avoiding deadlock
A takeaway from this is that deadlock is not the product of spark or JDBC connector. The deadlock will happen whenever there are multiple bulk import executing on single table irrespective of which applications initated the trasaction. Below are few approaches to avoid deadlock when using databricks to import large data into Azure SQL Server.
Coalesce partitions
We have already been using this solution throughout the blog. We coalesce the partitions to 1 in order to avoid concurrent bulk import. This is a tradeoff between performance and reliablility. We give up on the power of spark to execute multiple tasks concurrently to gain a deadlock-free execution. However this solution will not work if there are two or more notebooks running in parallel performing bulk import on the same table.
Insert into unique temp tables
This is a two phase approach. In first phase each worker bulk inserts data into different global temp tables which are exclusively created for this purpose. In the second phase each of these temp tables are merged into destination table. This two phase approach limits the surface area where deadlock can happen to second phase and that too only when multiple notebooks are running to bulk insert data into same table. This approach is available in Microsoft SQL Spark Connector with NO_DUPLICATES option on reliabilityLevel. However due to issue #22 this approach is not usable in databricks yet. An another problem with this approach is that spark can execute more than one tasks on same worker which will result in deadlock if temp tables are unique to a worker. This is being dicussed at issue #49.
Using Clustered Columnstore Index
Clustered Columnstore Index (CCI) is optimized for bulk insertion scenarios. If the batch size is greater than 102400 the rows are directly written to compressed columnstore. This means each task is writing into its own rowgroup which eliminates any possibility of deadlock. We have seen this scenario in the previous post. More details on how to optimize bulk insertion on CCI is available here.
Using Partitioned Table
Table partitioning in Azure SQL Database serves to spread the data into multiple units inside a single Primary filegroup. Partitioning the table helps to query and insert data into different partitions, in parallel, without one impacting the other. Since the operations in each Partition affect only a subset of the data in the table, they are more efficient than performing the operation on the entire table as one entity. In order to achieve an effective spread of this data into partitions, the choice of the Column in the table to partition on is important.
Choice of the column to partition on
In the scenario at hand, I have chosen to partition the table on the ss_store_sk Column in the Table dbo.store_sales, for the following reasons
- The number of rows in the table per
ss_store_skare in the same range of ~ 5 million - The Parquet data in the Azure Data Lake Store for store sales is already partitioned on this column
- Most commonly performed operations on the data in this table would be done based on the
ss_store_sk
This indicates that this column would be a good candidate to partition this Table on. A quick check on the distinct number of ss_store_sk values in the table indicated a count of ~ 1002. This means that we would need to create ~ 1003 partitions, providing for one partition that would store rows that have a null value for this Column. Azure SQL Database supports having upto ~ 15000 partitions per table.
The steps to be performed to partition tables are documented here. Follow through the sections below to see how this could be done.
Creating Partition Functions
DECLARE @IntegerPartitionFunction nvarchar(max) =
N'CREATE PARTITION FUNCTION partitionByStoreId (int)
AS RANGE RIGHT FOR VALUES (';
DECLARE @i int = 1;
WHILE @i < 1003
BEGIN
SET @IntegerPartitionFunction += CAST(@i as nvarchar(10)) + N', ';
SET @i += 1;
END
SET @IntegerPartitionFunction += CAST(@i as nvarchar(10)) + N');';
EXEC sp_executesql @IntegerPartitionFunction;
Creating Partition Scheme
CREATE PARTITION SCHEME PS_HASH_BY_STORE_SK
AS PARTITION partitionByStoreId
ALL TO ([PRIMARY]);
GO
Creating Partitioned Table
The Table dbo.store_sales has a combination Primary Key on the Columns ss_item_sk and ss_ticket_number. For us to partition this table on ss_store_s' Column, we would need to add this column to the Primary Key index. However, running the script below would result in an error, since the column ss_store_sk is nullable, and hence cannot be a part of a Primary Key. You would recollect that the data in the Parquet file contains rows where the ss_store_sk values are null, hence we need to be able to store null values in the Table. In order to address this, we would need to drop the Primary Index altogether, and instead create a separate Non clustered Index that includes all three columns.
DROP TABLE IF EXISTS dbo.store_sales
CREATE TABLE dbo.store_sales
(
ss_sold_date_sk integer ,
ss_sold_time_sk integer ,
ss_item_sk integer not null,
ss_customer_sk integer ,
ss_cdemo_sk integer ,
ss_hdemo_sk integer ,
ss_addr_sk integer ,
ss_store_sk integer null ,
ss_promo_sk integer ,
ss_ticket_number integer not null,
ss_quantity integer ,
ss_wholesale_cost decimal(7,2) ,
ss_list_price decimal(7,2) ,
ss_sales_price decimal(7,2) ,
ss_ext_discount_amt decimal(7,2) ,
ss_ext_sales_price decimal(7,2) ,
ss_ext_wholesale_cost decimal(7,2) ,
ss_ext_list_price decimal(7,2) ,
ss_ext_tax decimal(7,2) ,
ss_coupon_amt decimal(7,2) ,
ss_net_paid decimal(7,2) ,
ss_net_paid_inc_tax decimal(7,2) ,
ss_net_profit decimal(7,2) ,
index ui_stores_sales (ss_item_sk, ss_ticket_number,ss_store_sk)
--primary key (ss_item_sk, ss_ticket_number,ss_store_sk)
)ON PS_HASH_BY_STORE_SK (ss_store_sk) ;
Import into partitioned table
Now that the table has been partitioned, lets look at how we can bulk import store_sales using spark.
For the table partitions to be effectively leveraged during the Bulk Insert, the data in the spark dataframe also need to be partitioned on ss_store_sk, like the Database Table partitions. This ensures that a bulk insert from a Spark dataframe executes on a single table partition, without interfering with a Bulk Insert from another Dataframe. Not doing this will result in deadlocks as we discussed earlier.
Since our dataset in ADLS is already partitioned on ss_store_sk, spark will read it into different partitions, based on its size. On execution, it was observed that this resulted in 3 partitions per ss_store_sk. If the Bulk insert were performed thus, we would face deadlocks again. Unfortunately, there is no way to configure spark to read each file into single partition. What we will have to do is to repartition the dataframe again after reading the dataset from ADLS. This repartition will cause a SHUFFLE operation on spark which is a very costly operation. We can repartition dataframe on any column by simply supplying column name and number of partitions we want.
To demonstrate this we have created a new database that is partitioned on the column shown in scripts above. All DDL scripts is available in git repository linked at the begininning of the article. We will try to insert data for all 10 stores, which amounts to ~55 million records, as called out in the previous post.
def import_table_partn(url, table_name, stores, batch_size):
try:
df = spark.read.parquet(f"{path}/{table_name}")
df = df.filter(df[table_storesk_map[table_name]].isin(stores))
# Temporary workaround until Issue #5 gets fixed https://github.com/microsoft/sql-spark-connector/issues/5
table_schema = create_valid_table_schema(table_name, df.schema)
df = spark.createDataFrame(df.rdd, table_schema)
print(f"Number of partitions before repartitioning: {df.rdd.getNumPartitions()}")
df = df.repartition(len(stores), table_storesk_map[table_name])
print(f"Number of partitions after repartitioning: {df.rdd.getNumPartitions()}")
t = Timer(text=f"Imported into table {table_name} in : {{:0.2f}} ")
t.start()
df.write.format("com.microsoft.sqlserver.jdbc.spark") \
.mode("append") \
.option("url", url) \
.option("dbtable", f"{schema}.{table_name}") \
.option("user", username) \
.option("password", password) \
.option("tableLock", "false") \
.option("batchsize", batch_size) \
.save()
elapsed = t.stop()
return elapsed
except Exception as e:
print(f"Failed to import into table {table_name}", e)
url = create_url(server_name, "idxpartn")
truncate_tables(url, username, password, tables)
elapsed = import_table_partn(url, table_name, stores, 1048576)
If we take a look at the logs we will not find any deadlock errors. Moreover it took us only 593 seconds to insert data into partitioned table. Compare it with time it took insert data into non partitioned table from previous post. This is order of magnitude faster because we are able to insert data for each store in parallel.
Run the query below to find how many rows per partitions have been inserted.
SELECT TOP 10 object_name(object_id) as Table_Name,partition_id, partition_number, index_id, row_count
FROM sys.dm_db_partition_stats
WHERE object_name(object_id)='store_sales'
ORDER BY row_count DESC
query = """
SELECT TOP 10 object_name(object_id) as Table_Name,partition_id, partition_number, index_id, row_count
FROM sys.dm_db_partition_stats
WHERE object_name(object_id)='store_sales'
ORDER BY row_count DESC"""
url = create_url(server_name, "idxpartn")
dl_df = spark.read \
.format("jdbc") \
.option("url", url) \
.option("query", query) \
.option("user", username) \
.option("password", password).load()
display(dl_df)
You will notice partition_number is duplicated with different partition_id. This is because one row represents the table and the other non clustered index which is denoted by index_id. If you dont have a non clustered index and instead have a primary key then there will be only one partition representing clustered index created by primary key.
When carrying out the Bulk insert operation above, the target partitions were empty. There was no other application accessing the same table or partitions in that table. However, what if the partitions already had data in them, and other applications were actively connecting to it? This would then have an impact on the bulk insert that we are performing here, and potentially raise errors from deadlocks. The Spark Connector at this time does not provide the ability to Bulk insert into a separate staging table, which could then be merged with the main table using a partition switch. This feature is being discussed in [issue #46] (https://github.com/microsoft/sql-spark-connector/issues/46). Once this issue is resolved, we would have more options to deal with concurrency issues and deadlocks during Bulk insert operations.
def delete_tables(url, username, password, tables, stores):
for table in tables:
query = f"DELETE FROM {schema}.{table} WHERE {table_storesk_map[table_name]} IN ({','.join(map(str, stores))})"
try:
t = Timer(text=f"DELETE stores {','.join(map(str, stores))} from table {table} in: {{:0.2f}}")
t.start()
driver_manager = spark._sc._gateway.jvm.java.sql.DriverManager
con = driver_manager.getConnection(url, username, password)
stmt = con.createStatement()
stmt.executeUpdate(query)
stmt.close()
t.stop()
except Exception as e:
print(f"Failed to DELETE stores {','.join(stores)} from table {table}", e)
url = create_url(server_name, "idx")
delete_tables(url, username, password, tables, stores[:2])
As you could see, it took significant amount of time to delete the data of two stores. By default, a DELETE operation will acquire IX (intent exclusive) lock on table. With an intent exclusive (IX) lock, no other transactions can modify data; read operations can take place only with the use of the NOLOCK hint or read uncommitted isolation level.
Unlike SQL Server running in a Virtual Machine, Azure SQL Database does not provide the option to use a Simple Recovery Model. Instead it uses only the Full recovery Model. This implicitly requires a Log Backup to support a Full point-in-time recoverability of the data. Also, Azure SQL Database has a “Advanced Database Recovery” that uses a Persistent Version store to keep track of all changes that happen to the database. This allow Azure SQL Database to rollback a transaction instantaneously, no matter if the transaction has been running for hours or even days. This is the reason why DELETE and UPDATE Operations in Azure SQL Database take longer than SQL Server running on premises, or when compared to other Database Services in Azure.
Moreover DELETE operation gets complicated if its performed on Clustered Columnstore Index. It is recommended to avoid deleting large mount of data from CCI. When records are deleted from columnstore row it is logically marked as deleted (soft delete). A background task then runs that will determine if it is worth the effort to physically remove and merge the compressed rowgroups.
However if you are using partitioned table and needs to delete data from entire partition, you could perform a TRUNCATE operation instead of DELETE on the partition, by specifying partition id. This will be quickest and least resource intensive way to remove large data from the table.
With this I conclude this blog series on importing data into Azure SQL using Azure Databricks. If you have any questions or suggestions please leave them as comment below.