Building large scale data ingestion solutions for Azure SQL using Azure databricks - Part 2
Find out how bulk insert performs with different indexing strategy in Azure SQL Database.
Source Code

This is second part of 3 part blog series on importing large dataset in Azure SQL Database. In the previous post we discussed how Microsoft SQL Spark Connector can be used to bulk insert data into Azure SQL Database. We will be reusing the dataset and code from the previous post so its recommended to read it first.
In this post we will take a look how data ingestion performs under different indexing strategies in database. We will benchmark the results and compare them to understand what impact indexes had. While writing this post I noticed that the new new Microsoft SQL Spark Connector was taking much more time than my experience with now deprecated Azure SQL Spark connector. At the time of writing there is also an open issue on performance of the new connector. So I decided to take this opportunity to compare and see how well the new connector fairs agains the old one.
Environment
The number of Databricks workers has been increased to 8 and databases have been scaled up to 8vCore. To compare with old sql spark connector we need to install com.microsoft.azure:azure-sqldb-spark:1.0.2 from maven . Other than these changes the environment remains same as in previous post.
Indexing Strategies
We will discover how bulk insert performs against following 3 different indexing strategies -
- Rowstore Index: Rowstore indexes are the conventional way to store relational data, into a table with rows and columns, and physically stored in a row-wise format. The
store_salestable contains a clustered index (Primary Key). The table also has a non clustered index onss_store_skcolumn. These indexes are suited for OLTP Scenarios that entail highly concurrent operations on a subset of rows in the table. - Clustered Columnstore Index (CCI): With Clustered Columnstore Index, the data is stored in a columnar format. It is used in Data Warehousing scenarios to execute analytical queries. A columnstore index can provide a very high level of data compression and order of magnitude better performance than rowstore index when executing analytical workloads.
- Non-Clustered Columnstore Index (NCCI): A variant of CCI, the Nonclustered Columnstore index, is one that supports an Index in the columnar format, but over a rowstore table. This enables executing analytical queries on top of an OLTP Database, referred to as Operational Analytics. More details about the differences between the two Columnstore Indexes can be found here
We have different databases for each type of index. Approximately 55 million records from store_sales table will be inserted into them during benchmarking. The code for inserting records is same as in previous post except so I will skip the detail breakdown of it and few of the code blocks have been collapesd for brevity.
# List of table names
tables = ["store_sales"]
table_name = tables[0]
# Map between table names and store surrogate key
table_storesk_map = {
"store_sales": "ss_store_sk"
}
# Map between table names and schema
table_schema_map = {
"store_sales": [
StructField("ss_item_sk", IntegerType(), False),
StructField("ss_ticket_number", IntegerType(), False)
]
}
def truncate_tables(url, username, password, tables):
for table in tables:
query = f"TRUNCATE TABLE {schema}.{table}"
try:
t = Timer(text=f"Truncated table {table} in: {{:0.2f}}")
t.start()
driver_manager = spark._sc._gateway.jvm.java.sql.DriverManager
con = driver_manager.getConnection(url, username, password)
stmt = con.createStatement()
stmt.executeUpdate(query)
stmt.close()
t.stop()
except Exception as e:
print(f"Failed to truncate table {table}", e)
# Temporary workaround until Issue #5 gets fixed https://github.com/microsoft/sql-spark-connector/issues/5
def create_valid_table_schema(table_name, df_schema):
return StructType([x if x.name not in map(lambda n: n.name, table_schema_map[table_name]) else next(filter(lambda f: f.name == x.name ,table_schema_map[table_name])) for x in df_schema])
def import_table(url, table_name, stores, collapse_partitions=False):
try:
df = spark.read.parquet(f"{path}/{table_name}")
df = df.filter(df[table_storesk_map[table_name]].isin(stores))
# Temporary workaround until Issue #5 gets fixed https://github.com/microsoft/sql-spark-connector/issues/5
table_schema = create_valid_table_schema(table_name, df.schema)
df = spark.createDataFrame(df.rdd, table_schema)
print(f"Number of partitions: {df.rdd.getNumPartitions()}")
if collapse_partitions:
df = df.coalesce(1)
t = Timer(text=f"Imported into table {table_name} in : {{:0.2f}} ")
t.start()
df.write.format("com.microsoft.sqlserver.jdbc.spark") \
.mode("append") \
.option("url", url) \
.option("dbtable", f"{schema}.{table_name}") \
.option("user", username) \
.option("password", password) \
.option("tableLock", "false") \
.option("batchsize", "1048576") \
.save()
elapsed = t.stop()
return elapsed
except Exception as e:
print(f"Failed to import into table {table_name}", e)
The batchsize has been set to 1048576. This particular value is important when inserting into columnstore index. 1048576 is the maximum number of rows contained in rowgroup. Having batch size > 102400 rows enables the data to go into a compressed rowgroup directly, bypassing the delta store which greatly improves performance when bulk inserting data into columnstore index.
A boolean collapse_partitions argument is used to collapse the number of partitions to 1. This is done to avoid deadlock when inserting into rowstore index. When there are parititons in the dataframe, the SQL Spark Connector will initate bulk import for each of the partitions concurrently. This will result in multiple bulk inserts happening on same table which causes race conditions with Page Locks as more than one bulk import is writing to same page resulting in deadlock. We will discuss deadlock in more details later.
Rowstore index
CREATE INDEX idx_store_sales_s_store_sk ON dbo.store_sales (ss_store_sk) INCLUDE (
ss_sold_date_sk
,ss_sold_time_sk
,ss_item_sk
,ss_customer_sk
,ss_cdemo_sk
,ss_hdemo_sk
,ss_addr_sk
,ss_promo_sk
,ss_ticket_number
,ss_quantity
,ss_wholesale_cost
,ss_list_price
,ss_sales_price
,ss_ext_discount_amt
,ss_ext_sales_price
,ss_ext_wholesale_cost
,ss_ext_list_price
,ss_ext_tax
,ss_coupon_amt
,ss_net_paid
,ss_net_paid_inc_tax
,ss_net_profit
)
We have created a nonclustered index on ss_store_sk and included all the columns in it. This is because in our hypothetical use case we wish to retrieve all the columns of sales for a particular store. We import the records by coalescing the partitions to avoid deadlock issue that we witnessed earlier.
url = create_url(server_name, "idx")
truncate_tables(url, username, password, tables)
elapsed = import_table(url, table_name, stores, True)
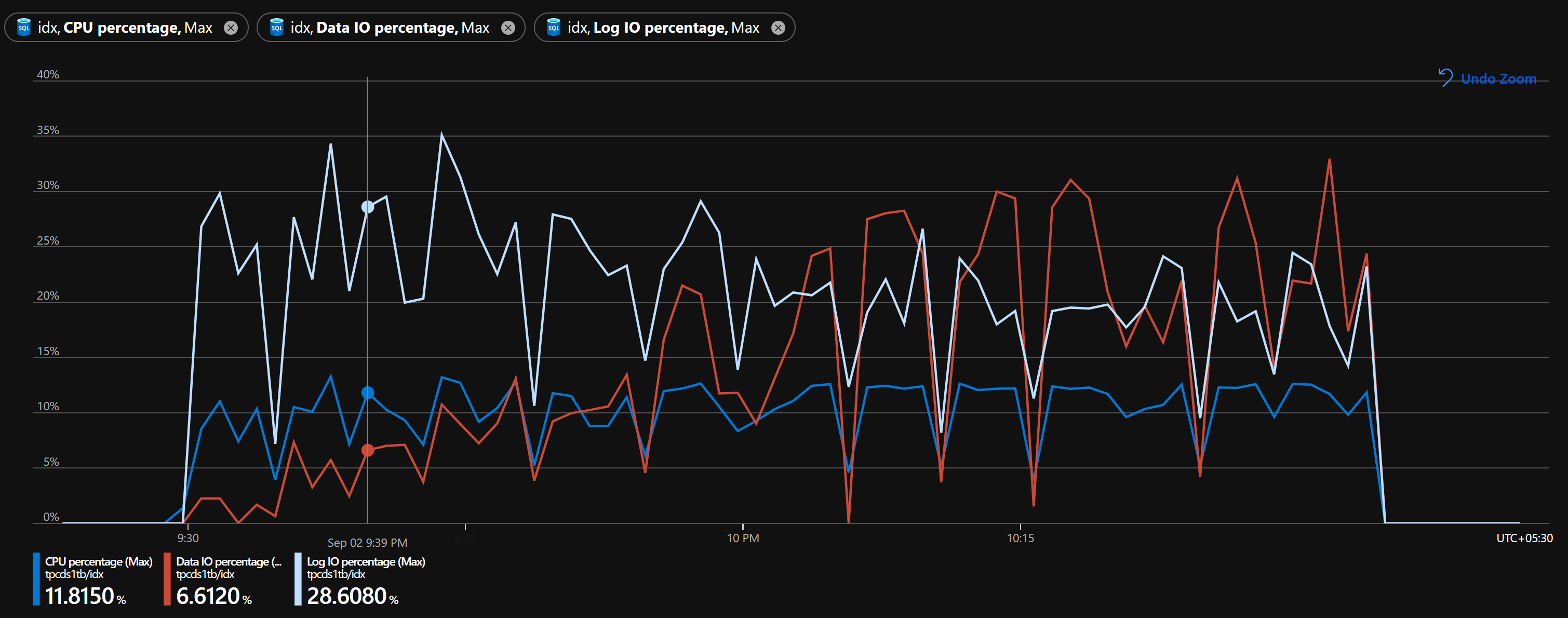
The database metrics captured from Azure portal shows the database is not throttled. Both CPU and IO are in comfortable range to allow any other operations to be performed in parallel.
Be mindful of locking behaviour of Bulk Insert. In the exmaples above in our database, page locks were acquired for each bulk insert. The page locks are held for the entirity of transaction of a batch (which is 1048576 records in this sample). This means any other write operation on same page will most likely fail or wait for the lock to be released. A lower batch size will mean locks are held for shorter period in exchange for increased number of batches and transactions. Depending upon your use case you will need to experiment with different batch sizes to determine what works best for you.
Clustered Columnstore Index
DROP TABLE IF EXISTS store_sales
CREATE TABLE store_sales
(
ss_sold_date_sk integer ,
ss_sold_time_sk integer ,
ss_item_sk integer not null,
ss_customer_sk integer ,
ss_cdemo_sk integer ,
ss_hdemo_sk integer ,
ss_addr_sk integer ,
ss_store_sk integer ,
ss_promo_sk integer ,
ss_ticket_number integer not null,
ss_quantity integer ,
ss_wholesale_cost decimal(7,2) ,
ss_list_price decimal(7,2) ,
ss_sales_price decimal(7,2) ,
ss_ext_discount_amt decimal(7,2) ,
ss_ext_sales_price decimal(7,2) ,
ss_ext_wholesale_cost decimal(7,2) ,
ss_ext_list_price decimal(7,2) ,
ss_ext_tax decimal(7,2) ,
ss_coupon_amt decimal(7,2) ,
ss_net_paid decimal(7,2) ,
ss_net_paid_inc_tax decimal(7,2) ,
ss_net_profit decimal(7,2)
);
CREATE CLUSTERED COLUMNSTORE INDEX cl_store_sales ON store_sales;
The clustered columnstore index (CCI) cannot be created on a table already having a clustered index on PK. So we drop and recreate the store_sales table without PK followed by creating a clustered columnstore index.
With the CCI we no longer need to coalesce the partitions as concurrent bulk insert will work just fine. CCI supports parallel bulk inserts to the same table so we can fully utilize our partitioned dataset to load the data concurrently.
The batch size 1048756 also plays an important role over here. Our aim is to bypass writing to delta rowgroup and directly write to compressed columnstore. The documentation has excellent explaination of this so I recommend reading it.
url = create_url(server_name, "cci")
truncate_tables(url, username, password, tables)
elapsed = import_table(url, table_name, stores, False)
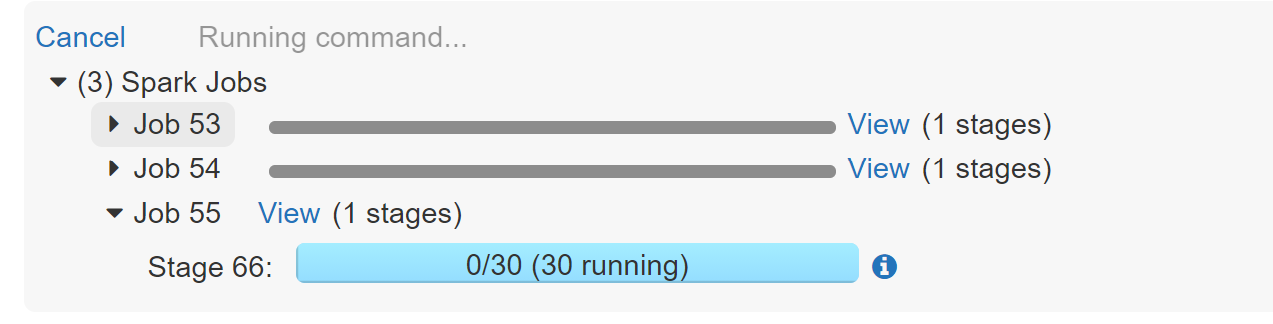
Since we did not coalesce the partitions multiple jobs were execution at same time as shown in image above. This resulted in much faster insertion of records in the database. Moreoever CCI are meant for large scale injestion scenarios and works great with bulk inserts and reads.
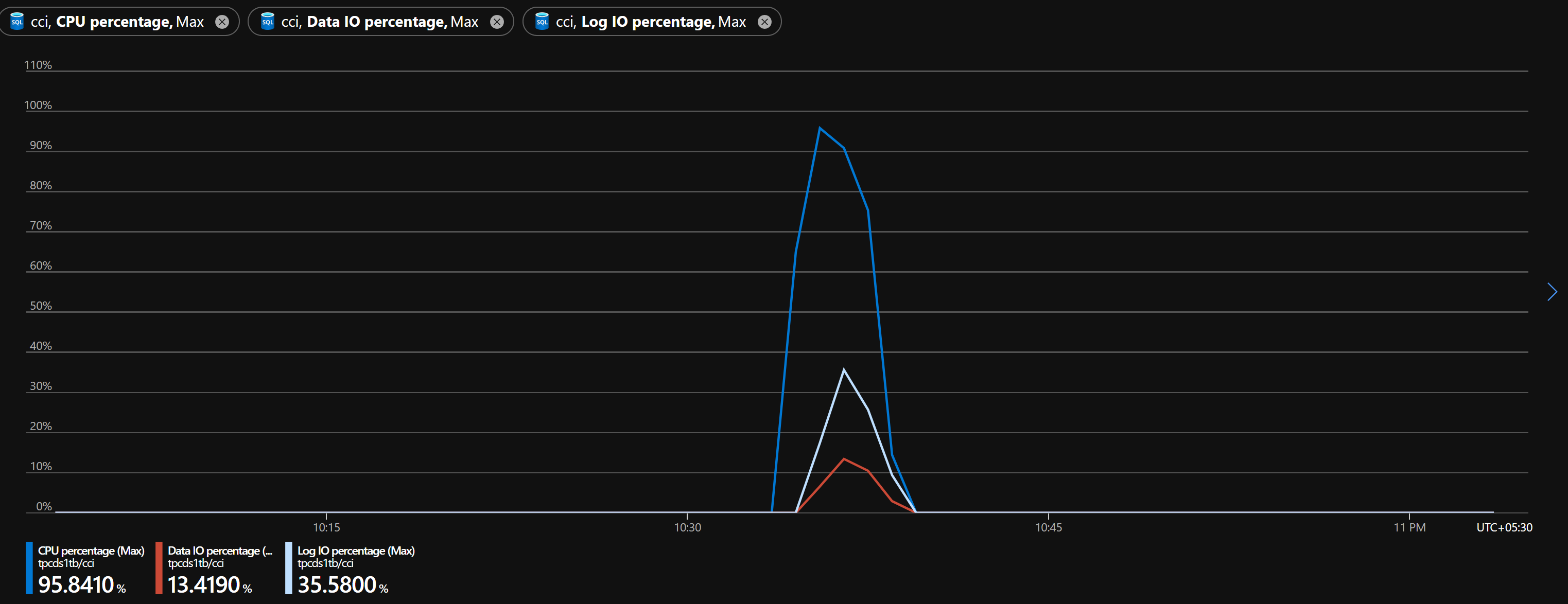
The CPU almost peaked during our run and that is because of multiple connections concurrently inserting large amount of data into the database. However the entire run completed in just over 4 minutes which is a very good performance.
Non-Clustered Columnstore Index
CREATE NONCLUSTERED COLUMNSTORE INDEX ncl_store_sales ON store_sales (
ss_sold_date_sk
,ss_sold_time_sk
,ss_item_sk
,ss_customer_sk
,ss_cdemo_sk
,ss_hdemo_sk
,ss_addr_sk
,ss_promo_sk
,ss_ticket_number
,ss_quantity
,ss_wholesale_cost
,ss_list_price
,ss_sales_price
,ss_ext_discount_amt
,ss_ext_sales_price
,ss_ext_wholesale_cost
,ss_ext_list_price
,ss_ext_tax
,ss_coupon_amt
,ss_net_paid
,ss_net_paid_inc_tax
,ss_net_profit
);
Something to keep in mind before deciding which column you want to include is that NCCI takes additional space to maintain, however the data is highly compressed. Here we create a non-clustered columnstore index (NCCI) with all the columns involved to benchmark worst case scenario.
Even though we have nonclustered columnstore index the physical storage of the data is still rowstore as the table has a Clustered Index on the Primary Key. That means concurrent bulk insert on same page will result to deadlock. So once again we have to coalesce the partitions.
url = create_url(server_name, "ncci")
truncate_tables(url, username, password, tables)
elapsed = import_table(url, table_name, stores, True)
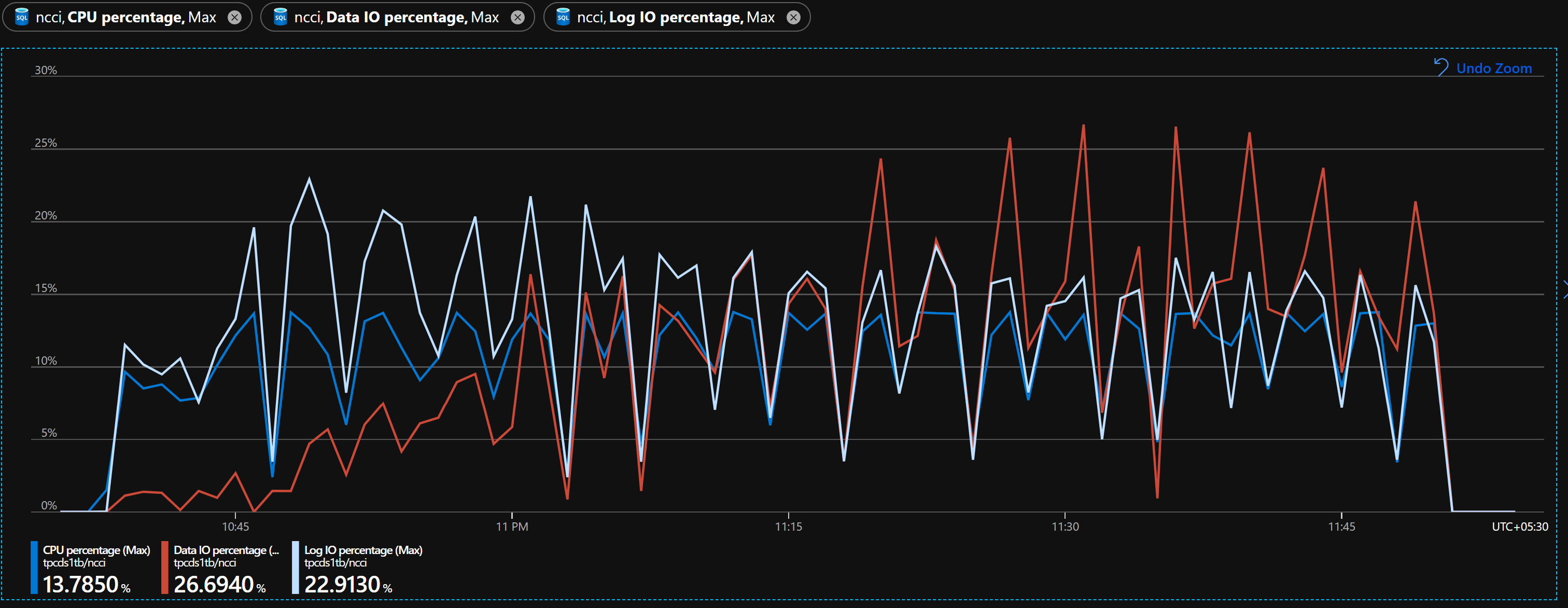
The database metrics for NCCI is very similar to that of rowstore. CPU or IO is not being throttled and are in comfortable range.
Comparing timings between different indexes
As we can see in the chart below there is drastic difference in time between clustered columnstore index and rowstore index. Because CCI is optimized for such workload and we are able to fully utilize the spark cluster to concurrently import the data, CCI performs bulk insert order of magnitude faster than rowstore index. Nonclustered Column Store Index does not have the same benefit as CCI. Even though both CCI and NCCI are based on same underlying columnar format, NCCI is a secondary index and the physical storage of data depends upon clustered rowstore index on Primary Key. So the performance of bulk import in NCCI is similar to that of rowstore. Inevitably either rowstore or NCCI would have performed better in this run however on average, when I ran this notebook multiple times, the rowstore and NCCI performed nearly identical. The real benefit of using NCCI is ability to perform real time analytics. Refer to this guide to choose best columnstore index for your needs.
Benchmarking using old Azure SQL Spark Connector
As mentioned before there is an open issue on poor performance of the new connector. I am following up with the developers of the connector to resolve it. Meanwhile lets run the bulk import on same three indexes to compare how well the new connector performs when compared to older one.
To get started we need to install the jar file from maven com.microsoft.azure:azure-sqldb-spark:1.0.2. The azure sqldb connector only works with Scala so we need to rewrite the above code in Scala. I will not get into details of the code but the following code is identical to what we have in python. At the end we will compare the run timings of old connector with new connector.
%scala
import com.microsoft.azure.sqldb.spark.query._
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
import org.apache.spark.sql.functions._
val path = "/mnt/adls/adls7dataset7benchmark/tpcds1tb/parquet"
var configMap = Map(
"url" -> dbutils.secrets.get(scope = "kvbenchmark", key = "db-server-name"),
"user" -> dbutils.secrets.get(scope = "kvbenchmark", key = "db-username"),
"password" -> dbutils.secrets.get(scope = "kvbenchmark", key = "db-password")
)
var df = spark.read
.parquet(path + "/store_sales")
.filter("ss_store_sk IS NOT null")
.groupBy("ss_store_sk")
.count()
.orderBy(desc("count"))
.limit(10)
val stores = df.select("ss_store_sk").collect.map(_.getInt(0))
def truncate_table(db:String, table_name: String) = {
val query = "TRUNCATE TABLE " + "dbo." + table_name
val config = Config(configMap ++ Map(
"queryCustom" -> query,
"databaseName" -> db
))
var start_table = System.nanoTime().toDouble
sqlContext.sqlDBQuery(config)
var end_table = System.nanoTime().toDouble
var run_time_table = (end_table - start_table) / 1000000000
println("Truncated table: " + table_name + " took: " + run_time_table)
}
def import_sales(db:String, table_name: String, coalesce: Boolean): Double = {
val config = Config(configMap ++ Map(
"databaseName" -> db,
"bulkCopyBatchSize" -> "1048576",
"bulkCopyTableLock" -> "false",
"bulkCopyTimeout" -> "7200",
"dbTable" -> table_name
))
var df = spark.read.parquet(path + "/" + table_name)
df = df.filter($"ss_store_sk".isInCollection(stores))
var tempdf = sqlContext.read.sqlDB(config)
var reorderedColumnNames = tempdf.schema.fields.map(_.name)
df = df.select(reorderedColumnNames.head, reorderedColumnNames.tail: _*)
println("Number of partitions: " + df.rdd.getNumPartitions)
if (coalesce == true) {
df = df.coalesce(1)
}
var start_table = System.nanoTime().toDouble
df.bulkCopyToSqlDB(config)
var end_table = System.nanoTime().toDouble
var run_time_table = (end_table - start_table) / 1000000000
println("Imported into" + table_name + " took: " + run_time_table)
return run_time_table
}
%scala
println("--- Starting import in rowstore index ---")
truncate_table("idx", "store_sales")
var elapsed = import_sales("idx", "store_sales", true)
var o_df = Map("rowstore"-> elapsed).toSeq.toDF("index_type", "time")
println("--- Starting import in CCI ---")
truncate_table("cci", "store_sales")
elapsed = import_sales("cci", "store_sales", false)
o_df = o_df.union(Map("cci"->elapsed).toSeq.toDF())
println("--- Starting import in NCCI ---")
truncate_table("ncci", "store_sales")
elapsed = import_sales("ncci", "store_sales", true)
o_df = o_df.union(Map("ncci"->elapsed).toSeq.toDF())
o_df.createOrReplaceTempView("o_df")
We can see that the old connector performance is much better than the new one when inserting into rowstore or NCCI but performs equally in case of CCI. I cannot emphasize enough that the old connector is deprecated and no more actively maintained. The new Microsoft SQL Spark connector is the future and just as with any new software it has bugs and issues. As it becomes mature it will be on par or exceed performance of the old connector. If you are already using old connector or have a dire need of best performance when inserting into rowstore index then you can continue using it before transitioning to new connector once the performance issue is fixed. There are also a lot of options that can be specified in connector to control the behaviour of bulk insert. Experiment with them and choose what fits best with your use case.
In the next post we will delve deeper into the issue of deadlock and discuss some solutions for it. Leave a comment if you have any questions or suggestions.